WTF?
This post was migrated from my old blog which used to be hosted on Blogger. As a result, some links might be broken.
When you are testing something - anything - you have some expectations as to what the result should be. The result either matches your expectations, or it does not. For example, you might want to find out what the person next to you will do if you shoot her in the face with a humble Nerf gun. Will she laugh? Shoot back? Kick your ass?
Many factors can affect the outcome of this test. Her current mood. Her attitude toward being shot in the face. The exact position where you hit her (cheek vs. eye). The frequency at which you repeat the test. What she was busy doing before the fact and how much you surprise her. Who’s watching can affect how embarrassed she will be. Bottom line: each time you perform the test, the variables will vary (get it? get it?). And the results can be different given the changing conditions.
You want a test to provide a reliable result each time. Because the alternative would mean you cannot trust single results, and may have to resort to averaging the results of many individual test runs. That’s unnecessary extra work and should be avoided.
You cannot guarantee reliable results if you do not control all the variables and moving parts of your test. Especially when they require human involvement, there’s always the chance that somebody does things in a slightly different order or timing. The slightest deviation from the other runs can affect the outcome and should make you distrust the results. This is one of the main reasons why software testing should be automated as far as possible, if not entirely.
So with that in mind, you’ve written some tests. They use a testing framework that has “unit” in it’s name, which means that they are unit tests. Right? Try again. Unit tests are supposed to focus on the behavior of a particular unit, nothing more and nothing less. Definitions of “unit” may vary, but it’s often a class. If unit tests are not properly isolated, they will have more dependencies than are necessary for what you are trying to test. More moving parts. More things you need to control, but often can’t. More things that are going to void your test results.
Tests that execute differently each time they run are called mutating tests. Dependencies that can skew your results are often inputs that they do not entirely “own”, e.g. values from a database or shared files on a network. If those values change, your test changes.
There are also rather less obvious mutagens that can have the same effect, for example:
DateTime.Now will be different every time your test runsMutation testing can in fact be a way to test your tests. Modify the logic-under-test and you should see some of your tests fail. This practice appears to be rather academic as I still have to come across somebody who actually uses mutation testing in the real world.
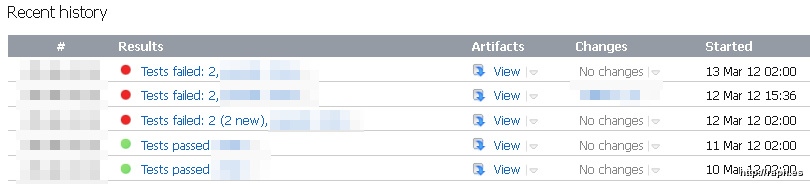
The problem with mutating tests is that you only notice them when they fail. This is worrying as it makes you wonder how many tests are mutating in ways that prevent them from failing when the actually should… In the following recent real-life case, two tests were failing even though there were no changes to the code.
WTF?
When I ran the same tests from the same version of the code locally on my machine, they passed. My spider-senses tingled: mutating tests! After looking at the build times I noticed that they began failing on March 12, and since then consistently failed. That indicates a temporal dependency.
After some investigation I discovered that the code-under-test used the .NET property Environment.TickCount to capture points in time and compare them. TickCount is an Integer and counts the milliseconds since the host machine was started. It starts at 0, counts up to 2147483647 (= Int.MaxValue), then wraps around to -2147483648 (= Int.MinValue) and goes up towards 0 again.
The code-under-test compared the TickCount value against a fake count of 1. The difference determined the outcome of the test. It was positive until the TickCount went beyond Int.MaxValue and wrapped into the negative - where it suddenly turns into a very negative one.
I did some very complicated math to find out how long a machine would have to run until the TickCount reaches Int.MaxValue:
2147483647ms / 1000ms / 60s / 60min / 24hr = ~24.86 days
Typically I will reboot my dev machine every few days, but the build agents often run for weeks without a reboot. That would explain why the tests pass on my machine, but not on the build server.
Enough of the theories, let’s have some proof. TeamCity can show you when an agent has registered with the server - which I know will happen automatically every time the agent host boots up.
When did my build agent last reboot?
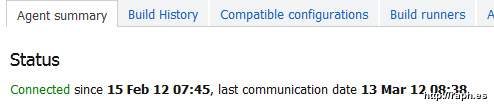
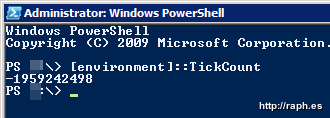
So it started up on Feb 15. That’s just about exactly 25 days before the tests started to fail. The TickCount must have wrapped into the negative. So there’s one more thing to do to prove it: using PowerShell you can call that same TickCount property and see what value it has. And sure enough…
PowerShell gives you direct access to .NET methods
All that had to be done now is reboot the build servers, and the tests passed fine again!
Not.
We stubbed out the call to Environment.TickCount so we can control it in the tests, better isolating them from the environment.
And now the world is a little bit safer.